KAMP 사례 중 공정 데이터로 설비 이상 탐지하는 사례를 요약 정리하였음. 대부분 사례에서 설비 이상 상태가 정의되어 있지 않아 도메인 지식을 바탕으로 설비 이상 상태 라벨링 후 분석 진행함.
출처: https://www.kamp-ai.kr/aidataList
l 사례 요약
| 공정 | 이상 상태 | 방법론 | 데이터 수집 |
| 열처리 공정 설비 | IQR 범위로 판정 | Auto encoder |
건조로 온도, 소입로 온도 등 공정 데이터 |
| 다이캐스팅 공정 주조 설비 |
가생산 상태(예열) 진단 검수자가 불량품 선별 |
Random Forest |
Shot 번호, 속도, 실린더 압력 등 공정 데이터 |
| 사출 성형 공정 (IP Injection 유사 공정) |
LOT 별 IQR 범위, DBSCAN |
Auto encoder, DBSCAN |
LOT 단위 분석, 배럴 온도, 호퍼 온도, 압력 등 공정 데이터 |
| 배터리팩 용접기 공정 | 검수자가 불량품 선별 후 해당 시점 공정 데이터 분석 | N-HITS 시계열 예측, Z-score |
용접시퀀스, 속도, set power, real power 등 공정 데이터 |
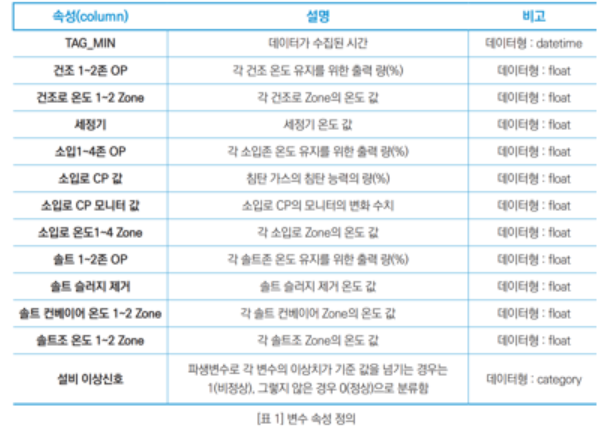
1. 열처리 공정 설비
공정 설명:
열처리 전기식 가열 설비로 설비 내부 860도 온도로 내부 상태 파악이 어려움
AUSTEMPER를 목적으로 설계되었으며 입구 PUSHER에서 로체로 장입한 후에 AUSTEMPER → 추출 → SALT 소입 → 추출 등의 작업이 자동으로 이루어지는 공정
이상 상태 판정:
정상 기준치를 IQR 범위로 설정하고 벗어날 경우 이상치로 판정
주요 변수 중 9개 이상이 이상치일 경우 설비 이상으로 판정 → 설비 이상신호로 라벨링 후 분석
수집 데이터 항목:
방법: Auto Encoder
1. 정상 데이터와 비정상 데이터 구분, 라벨링
- 변수 항목 중 이상치 개수가 9개 이상이면 설비 이상으로 라벨링
- 정상 데이터와 비정상 데이터(설비 이상) 구분
-
2. 정상 데이터만 Auto Encoder로 학습
- Encoder로 학습 후 Decoder로 복원
- 복원한 데이터(정상적인 특성 반영)와 실제 데이터와의 차이 비교
-
3. 복원값 ~ 실제값의 차이에 따라 설비 이상 판정
- 차이의 임계점 설정 필요
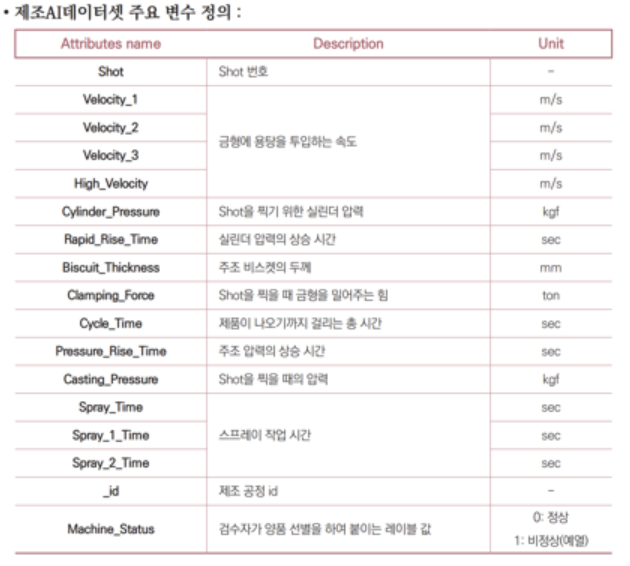
2. 다이캐스팅 공정 주조 설비
공정 설명:
다이캐스팅은 금형을 이용하여 용융 금속을 금형 내에 높은 압력으로 빠르게 주입하는 장치이며, 용탕의 냉각 속도가 빠른 주조법 공정
이상 상태 판정:
예열 상태(가생산)에서 생산하는 제품은 불량으로 폐기됨
설비 가생산 상태를 설비 비정상으로 간주하나 두 상태 구분이 어려움
알고리즘으로 각 Sholt 별로 예열을 위한 설비 가생산 상태를 자동 진단하는 것이 목적
데이터 수집 항목:
방법: Random Forest, 앙상블
1. 설비 상태(정상, 예열 가생산)를 입력하여 데이터 생성
- 현업에서 설비 상태 수기 입력하여 라벨링
2. 데이터 전처리 진행
- 정상/비정상 클래스 불균형 해결 over sampling
- Scaling 등
3. Random Forest 모델 생성, 주요 인자 추출
- Cycle Time, High Velocity, Biscuit thikness, clamping force, casting pressure, machine status
4. 주요 5개 인자를 중심으로 설비 정상 관리 범위를 지정함
- 주요 인자의 IQR범위를 벗어날 경우 이상치로 판단
- 정상 관리 범위 정하고 그 안에서 설비 운영
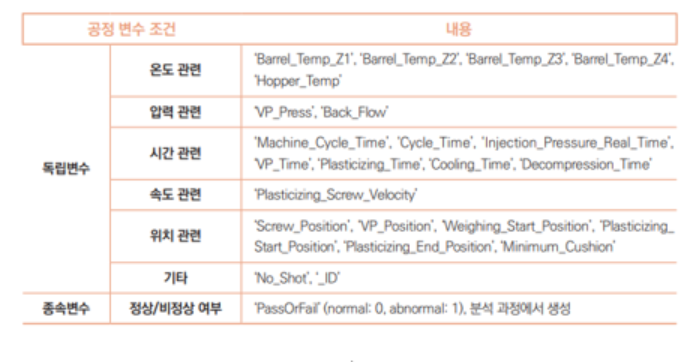
3. 사출 성형기 공정
공정 설명:
플라스틱과 같은 합성수지 등의 재료를 가열해서 녹이고 금형에 주입한 뒤 냉각시켜 원하는 가공품을 생산하는 제조방법
이상 상태 판정:
LOT 단위로 분석 진행
통계: LOT 단위 대표값, IQR 범위 기반으로 이상치인 변수가 N개 이상이면 비정상 LOT로 라벨링
DBSCAN: PCA(주성분 분석)으로 변수들 차원을 축소한 후 2차원 공간에 그림. PCA한 것을 밀도 기반 클러스터링인 DBSCAN으로 멀리 떨어진 것들을 비정상으로 분류함

데이터 수집 항목:
방법: Auto Encoders
1. 이상 상태 판정 방법에 따라 정상으로 판정된 데이터만 분리
- IQR, PCR, DBSCAN 등으로 이상치 분류 후 정상 데이터만 학습
2. Auto Encoder로 정상 데이터만 학습
3. 실제 데이터에 훈련한 모델 적용, Encoder -> Decoder로 복원 후 데이터와 실제값이 임계치 이상으로 다를 경우 이상 LOT로 진단
기본적으로 Lot 단위로 대표값을 설정하여 abnormal Lot을 판단하여 전체 데이터에 대한 설비의 normal, abnormal 레이블을 부여하기 때문에 Lot 단위 데이터 수집 체계를 전제로 한다
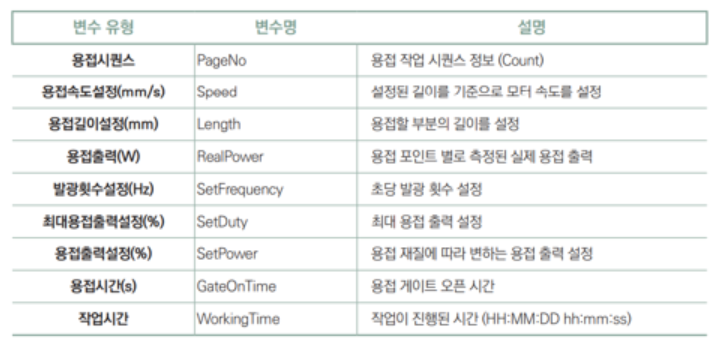
4. 전자 부품 배터리셋 용접기
공정 설명:
배터리팩 모듈 조립 과정에서 용접하는 공정
전기버스 및 전기상용차에 사용되는 배터리팩을 조립/생산하는 시스템으로 최소 단위인 배터리셀을 검사/조립하는 공정, 그리고 양품인 배터리셀들을 모듈화하여 조립/용접/검사하는 공정, 마지막으로 완성된 배터리모듈을 모아 조립/검사/시험 공정을 거쳐 배터리팩이 완성됨
이상 상태 판정:
1. 출고 검사 인원이 용접이 완료된 배터리모듈 품질을 검사, 양품/불량을 판정
불량 판정 시 용접 설비 알람 이력, 일시를 기록하여 공정 데이터와의 상관관계 분석 진행함
2. Setting power 대비 실제 용접 출력값 real power 분석하여 이상 상태 구분
Real power 이상 출력은 두 가지로 나뉨
고립된 시점 real power가 정상에서 벗어날 때와 연속적인 시간 구간에서 비정상적일 때
각각 다른 알고리즘 적용
데이터 수집 항목:
방법1: N-Hits 시계열 예측
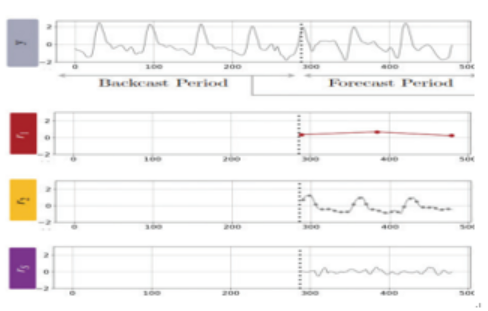
정상 데이터 출력 중 비정상이 짧은 순간 고립된 시점에서 발생하는 경우 N-Hit 시계열 알고리즘을 적용함
N-HiTS 시계열 알고리즘에서는 큰 흐름의 예측, 중간, 세밀한 흐름으로 스택을 나누어 예측 후 합침
1. Real Power(실제 용접 출력) 데이터 전처리하여 정상적인 데이터 구간 생성
- setting power 참고하여 온도군이 다를 경우 일정 값을 더하여 맞춰줌. 예를 들어 1620~1820 범위의 값들과 600 전후의 값으로 그룹이 나누어지고 두 값 모두 정상일 경우 600전후의 값에 1000을 더하여 비슷한 범위의 값으로 평준화
- 이상치, 결측치 제거
2. N-HiTs 알고리즘 적용
- 입력 길이 구간 20, 예측 구간 길이 10로 학습 및 예측
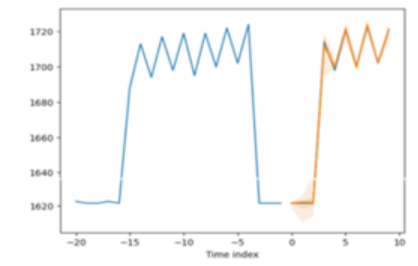
3. 예측값 대비 실제값 차이 크면 비정상 간주
-긴 구간의 비정상 데이터에 대해서는 예측력이 떨어짐
-정상 데이터 중 고립된 시점 발생하는 비정상(스파이크 형태) 예측 우수
방법 2 : Z-score 이상치 판단
긴 구간에 걸쳐 비정상 데이터가 발생하는 경우 통계적 분석(Z-score)로 이상치 판정
1. 구간 별 정규 분포를 가정, 평균값과 표준편차 등의 통계값 계산
2. 새로운 데이터가 구간 별 분포와 통계값에서 임계치 이상 다를 경우 이상 판정
요약하자면, 품질 양품 검사를 통해 제품 불량 판정 시 해당 기간의 공정 데이터를 비정상으로 라벨링함. 비정상 데이터와 정상 데이터의 특성을 분석하고, 비정상 데이터의 종류에 따라 각기 다른 알고리즘을 적용함. 짧은 구간의 스파이크 형태 비정상 데이터는 시계열 분석 N-HiTS 알고리즘, 긴 구간의 비정상 데이터는 통계적 분석 방법인 Z-score를 적용하였음
'Research > 스마트 팩토리' 카테고리의 다른 글
| CMMS 고장 데이터 분석 참고자료 (0) | 2022.05.20 |
|---|---|
| 빅데이터 기반의 스마트 제조업에 대한 단상 (0) | 2022.04.25 |
| 공정 품질 사전 예측 및 예지보전 위한 데이터 마이닝 (0) | 2022.04.05 |
| 챗봇 업체 research (비공개) (0) | 2022.04.05 |
| 예지보전(Predictive maintenenance)을 통한 다운타임 방지 (0) | 2022.04.05 |



댓글